Quelle est la première chose que vous avez écrite sur le web ? Un poème embarrassant pendant votre adolescence ? Un compte rendu de match pour le club de football local ? Avez-vous par la suite écrit de nombreux messages sur des forums de discussion ouverts ? L’écriture est-elle devenue une partie intégrante de votre travail, de sorte que vous avez commencé à vivre de textes protégés par des droits d’auteur ?
Ou avez-vous publié des photographies, voire des dessins ?
Si oui, vous pouvez compter que vos créations ont été utilisées par Open AI pour entraîner des systèmes d’IA tels que GPT, le modèle derrière le robot linguistique Chat GPT, ou des systèmes similaires qui créent des images.
Ont-ils demandé la permission ? Non. Ont-ils le droit de le faire ? Très probablement. Mais ce n’est pas le dernier mot. La question des données d’entraînement pour les systèmes d’intelligence artificielle est en train de se transformer en une énorme bataille sur les droits d’auteur, la technologie et le fonctionnement de l’internet du futur.
La décision sera en grande partie prise par les tribunaux. L’agence d’images Getty Images a intenté un procès à la société à l’origine du générateur d’images d’IA Stable Diffusion. À l’automne dernier, l’auteur de fantasy George R.R. Martin et d’autres ont poursuivi Open AI. Pendant les vacances de Noël, le New York Times a fait de même, en visant également Microsoft.
« Ils essaient de faire fi de l’énorme investissement du Times dans son journalisme », a écrit le journal dans sa plainte.
Open AI a réagi, et avec un message poliment formulé qu’ils ont l’intention de klaxonner et de s’enfuir. En effet, sans l’utilisation de matériel protégé par le droit d’auteur d’autrui, les systèmes d’IA d’aujourd’hui ne pourraient pas exister, affirment-ils.
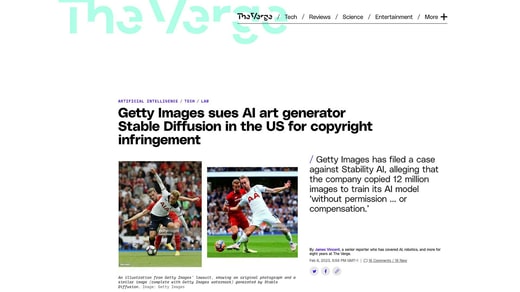
Photo : The Verge
« Parce que les droits d’auteur actuels couvrent presque toutes les expressions humaines – y compris les articles de blog, les photographies, les articles de forum, les morceaux de logiciel et de code, les documents gouvernementaux – il serait impossible de former les principaux systèmes d’IA d’aujourd’hui sans matériel protégé par des droits d’auteur », écrit l’entreprise dans un document soumis au Parlement britannique.
On pourrait faire remarquer que The Pirate Bay n’aurait pas pu exister sans le matériel protégé par le droit d’auteur d’autres personnes. Mais la conclusion que beaucoup en tirent est que The Pirate Bay doit disparaître. Non pas que le droit d’auteur doive être aboli.
En même temps, le parallèle avec le piratage n’est pas simple.
Oui, les géants de l’IA profitent du travail des autres. Certains exemples deviennent parodiquement évidents. Prenez Greg Rutkowski, un dessinateur polonais de sujets fantastiques, comme les dragons, les épées et les sorciers. Ses images ont été utilisées pour entraîner les systèmes d’imagerie de l’IA, à tel point que son propre nom sert de sifflet au système pour créer une image dans son style particulier. Tapez ce que vous voulez voir, par exemple « dragon dans une grotte en train de se battre » et ajoutez « Greg Rutkowski », et le système d’IA saura ce que vous voulez dire. Pour lui, l’inconvénient est clair : il aura plus de mal à vendre ses images si vous pouvez les générer rapidement et à peu de frais.
Et ces images fantaisistes de l’IA n’auraient pas pu exister sans son travail.
Mais s’agit-il d’une violation du droit d’auteur ? Pas exactement. Les images produites ne sont pas des copies exactes, elles imitent simplement son style. Tout comme l’écriture, la photographie ou la peinture d’une personne sont influencées par tout ce qu’elle a vu et lu, le système d’IA a analysé le matériel d’entraînement, trouvé des modèles et appris à créer les siens.
Si je lis 100 romans policiers, ma perception de l’organisation d’un roman policier s’en trouve affectée. Si je vois 100 dessins de dragons fantastiques polonais, cela peut m’apprendre à dessiner les miens. Lorsque les gens le font, personne ne peut prétendre qu’il y a violation du droit d’auteur.
Mais l’échelle est bien plus grande lorsque les systèmes d’IA sont prêts à mâcher tout ce qu’ils trouvent sur le web. Et l’enjeu est bien plus important : l’Open AI serait aujourd’hui évaluée à environ 100 milliards de dollars.
Avec tant de choses à aucun des principaux acteurs de l’IA ne ralentira sans que quelqu’un ne l’y oblige. Cela suit un schéma familier de la Silicon Valley. Il fut un temps où Google indexait l’ensemble du web pour le rendre consultable. Cela a donné lieu à quelques batailles juridiques, mais une trêve a été conclue parce qu’il y avait un intérêt mutuel entre Google et ceux dont les sites étaient indexés. Google pouvait faire fonctionner son moteur de recherche et, en échange, les propriétaires de sites recevaient des visiteurs.
Un tel équilibre n’existe pas dans le développement de l’IA. Au contraire, je ne gagne rien à ce que mon texte soit utilisé pour entraîner Chat GPT. Greg Rutkowski n’a rien à gagner des images de dragons. Microsoft et Google construisent des moteurs de recherche qui répondent aux questions plutôt que d’envoyer les visiteurs vers d’autres sites. Des réponses qu’ils ont recueillies auprès de sources en ligne qui – oui, ne rapportent rien. L’exception est constituée par certaines entreprises de médias qui ont signé des accords avec Open AI, mais le procès intenté par le New York Times montre qu’il ne s’agit pas d’une pratique généralisée.
Non, jusqu’à présent, les géants de l’IA se sont gavés de ce qu’ils ont trouvé. J’ai d’ailleurs posé cette question au PDG de Google, Sundar Pichai, lorsque je l’ai interviewé l’été dernier. « Nous participerons à la discussion et trouverons la bonne approche au fil du temps », a-t-il répondu.
Mais en attendant les accords, ils klaxonnent et conduisent. Vous devrez régler les questions juridiques plus tard.
Mieux vaut s’excuser que demander la permission.
Erik est né et a grandi à Stockholm, en Suède, où il a passé la majeure partie de sa vie avant de venir vivre en France en 2018. Il est de langue maternelle suédoise et parle couramment francais. Il a obtenu un diplôme en communication et marketing à l’Université de Stockholm. Passioné par les voyages et la culture Suédoise, il aime partager les infos et valeurs de la Suède.